
Зачем делать бэкап в BigQuery?
Итак, вы используете BigQuery для аналитической работы со своими данными.
К сожалению, в BigQuery нет «родного» механизма резервного копирования таблиц. Google резервирует данные клиентов достаточно надежно, чтобы гарантировать их сохранность от своих сбоев и аварий.
Однако если таблица будет удалена или изменена, восстановить ее нельзя (точнее, можно, но только в течение двух дней). Причиной нежелательных изменений таблиц могут быть человеческий фактор, ошибки при автоматическом импорте и т. д. Кроме того, иногда полезно сохранять историю изменений таблицы.
Бэкап средствами Google
Предлагаемое решение внедрено в eLama и будет особенно интересно компаниям, использующим инструментарий Google Cloud Platform. А если вы его не используете, то это отличный повод начать.
Как это работает? Таблицы, требующие регулярного бэкапа, по расписанию копируются в облачное хранилище Google Cloud Storage в виде json-файлов по соответствующему пути.
При этом наши таблицы в BigQuery можно разделить на:
- одиночные постоянные. Они создаются один раз и никогда не меняются;
- датированные вида tableName_20190612. Создаются с некоторой периодичностью
(например, данные о посещениях сайта за сутки); - одиночные обновляемые. В них данные регулярно дополняются новыми строками
(например, список рекламных кампаний).
Постоянные таблицы копируются один раз вручную. При этом к имени json-файла добавляется постфикс, содержащий дату копирования.
Датированные также копируются разово, но автоматически и регулярно. Частота бэкапа равна периодичности возникновения этих таблиц. Когда таблица создается, она копируется в GCS. При этом бывает, что таблица еще пару дней дописывается. (Например, стриминг через OWOX посещений и событий из Google Analytics создает суточные таблицы каждый день, но заканчивает запись в них в течение двух-трех дней.) Для таких случаев механизм бэкапирования перезаписывает в GCS последние три-четыре таблицы: те, что были изменены, и одну-две не измененных — «на всякий случай».
Одиночные обновляемые таблицы копируются в одну папку в GCS с постфиксом в названии файла в виде даты с периодичностью их обновления (например, ежедневно). В итоге мы имеем историю версий таблицы за период, равный сроку хранения бэкапа, в виде:
TableName_20190415
TableName_20190416
TableName_20190417
...
TableName_20190614
TableName_20190615
Срок хранения бэкапа задается в скрипте (например, два месяца). По истечении срока хранения файл автоматически удаляется из GCS, чтобы не захламлять хранилище.
Google Cloud Storage как хранилище резервных копий
Достоинство GCS в хорошей совместимости с другими продуктами Google, высокой надежности и низкой стоимости.
При этом надо понимать, что GCS не файловый менеджер, а именно хранилище. Здесь нет дерева каталогов в привычном понимании, «путь» к файлу виртуален, это лишь часть имени файла, а такого объекта как «папка» не существует. Поэтому невозможно, например, вручную перенести множество файлов из одного каталога в другой, так как нет механизма массового переименования.
Также нет возможности задать срок жизни конкретного файла — только для всего бакета сразу.
Однако все эти манипуляции можно выполнять программно через скрипты, обращающиеся к GCS по API.
В рассматриваемом решении резервные копии хранятся в GCS в виде:
- {bucket}/{project}/{dataset}/{tableName}_{copyDate}.json — для постоянных таблиц,
- {bucket}/{project}/{dataset}/{tableName}/{tableName}.json — для датированных таблиц,
- {bucket}/{project}/{dataset}/{tableName}/{tableName}_{copyDate}.json — для обновляемых таблиц,
где
- {bucket} — имя бакета в GCS,
- {project} — имя проекта в BigQuery,
- {dataset} — имя датасета в BigQuery,
- {tableName} — имя таблицы в BigQuery (для датированных таблиц в качестве постфикса включает дату создания таблицы),
- {copyDate} — дата копирования таблицы вида ггггммдд.
Google AppScript как инструмент автоматического копирования
GAS — замечательная технология, позволяющая связать разные сервисы Google и добавить им функциональности, которой не хватает для ваших нужд. Пишем скрипт на js, настраиваем запуск
по расписанию и не заботимся о каком-либо стороннем софте.
Итак, наша задача — написать скрипты, которые:
1) экспортируют таблицы из BigQuery в GCS в виде json-файлов (BigQuery использует формат JSON Newline Delimited);
2) по истечении срока хранения бэкапов удаляют их.
Экспорт таблиц из BigQuery в GCS
Для экспорта таблиц в GCS с помощью GAS используем метод создания работы в BigQuery: BigQuery.Jobs.insert(). Код скрипта здесь.
Автоудаление устаревших бэкапов
Эта задача посложнее. Встроенной библиотеки для работы с GCS у AppScript нет, поэтому придется обращаться к хранилищу по API. Алгоритм следующий:
1. Включить API GCS в консоли Google Cloud.
1.1. Открываем Cloud Console и переходим в раздел APIs and Services.
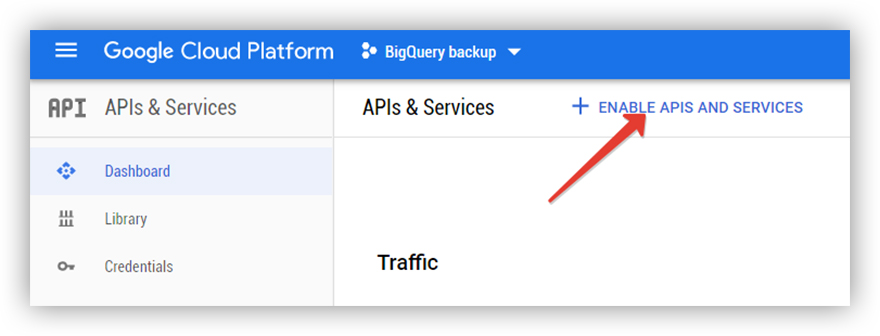
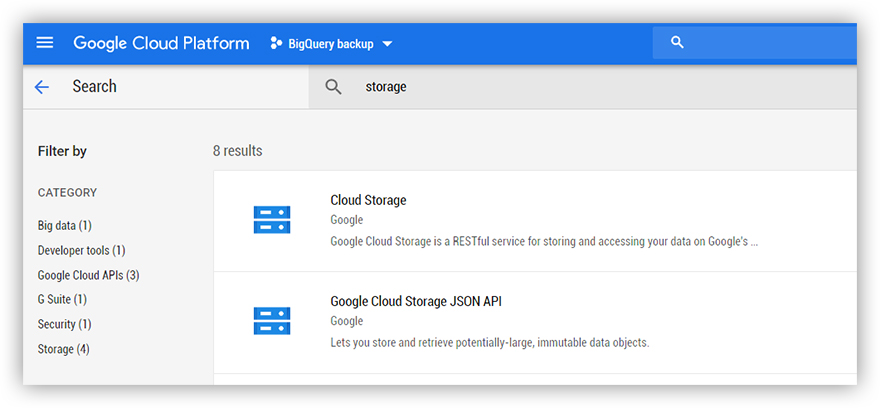
1.2. Подключаем API GCS.
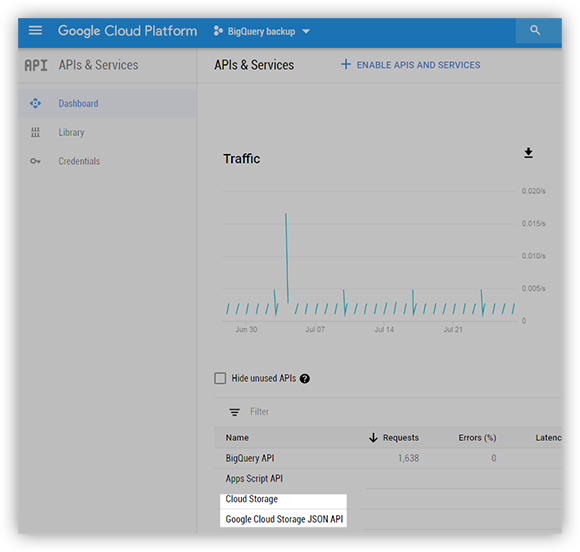
Вернувшись в раздел APIs and Services, убедимся, что нужные API подключены.
2. Настроить права.
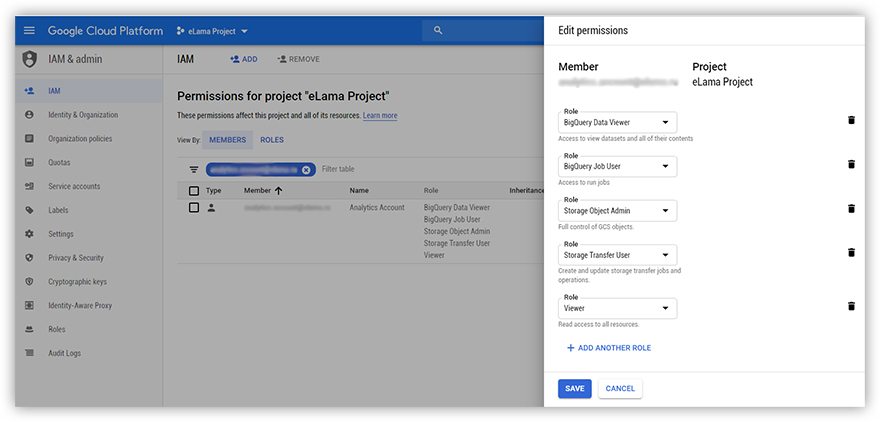
Дадим пользователю, от имени которого будет запускаться скрипт, права на доступ к объектам в GCS. Открываем Cloud Console — IAM – находим пользователя и создаем для него роли:
BigQuery Data Viewer
BigQuery Job User
Storage Object Admin
Storage Transfer User
Viewer
3. Разрешить доменное делегирование.
Чтобы наш скрипт мог работать с файлами GCS без ручной авторизации, нужно настроить делегирование полномочий по домену (укажите API Scope, который дает полномочия управлять объектами в GCS: https://www.googleapis.com/auth/devstorage.read_write). Тогда пользователь, чей аккаунт находится
в корпоративном домене (мы дали ему права в предыдущем пункте), сможет использовать API GCS. Авторизация происходит через учетную запись для сервисного аккаунта Google в службах OAuth2.
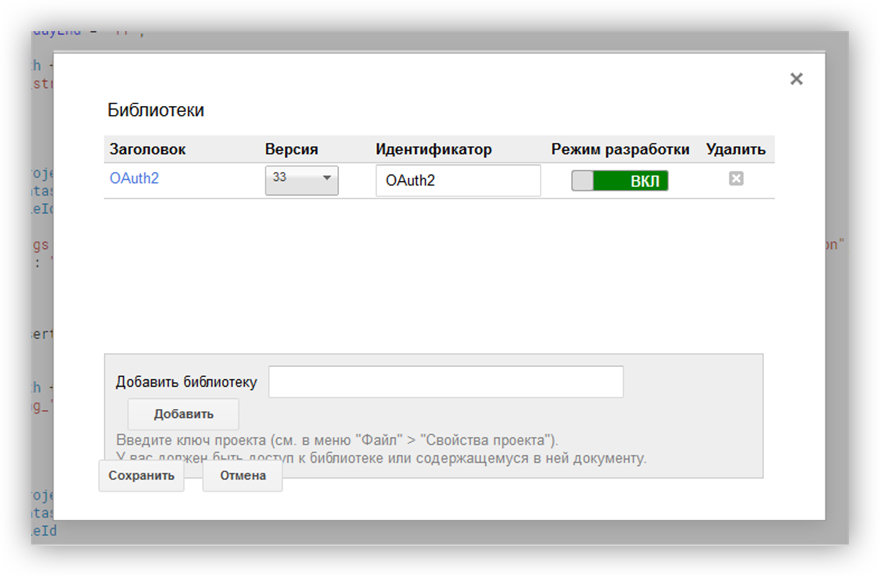
4. Подключить библиотеку OAuth2 авторизации.
Для правильной работы скрипта подключим библиотеку OAuth2 for Apps Script.
В интерфейсе GAS открываем меню «Ресурсы» — «Библиотеки...». Вводим ключ библиотеки 1B7FSrk5Zi6L1rSxxTDgDEUsPzlukDsi4KGuTMorsTQHhGBzBkMun4iDF, жмем «Добавить».
5. В скрипте обращаться к API.
Скрипт удаления устаревших бэкапов здесь.
Настройка расписания скриптов
Определившись с частотой обновления таблиц (то есть запуска скрипта резервного копирования), переходим к настройке триггеров, запускающих скрипты.
1. В проекте GAS нажимаем иконку и переходим к списку триггеров.
2. Создаем новый триггер, указываем главную функцию скрипта, расписание запуска и частоту уведомлений об ошибках.
3. Жмем «Сохранить». Готово.
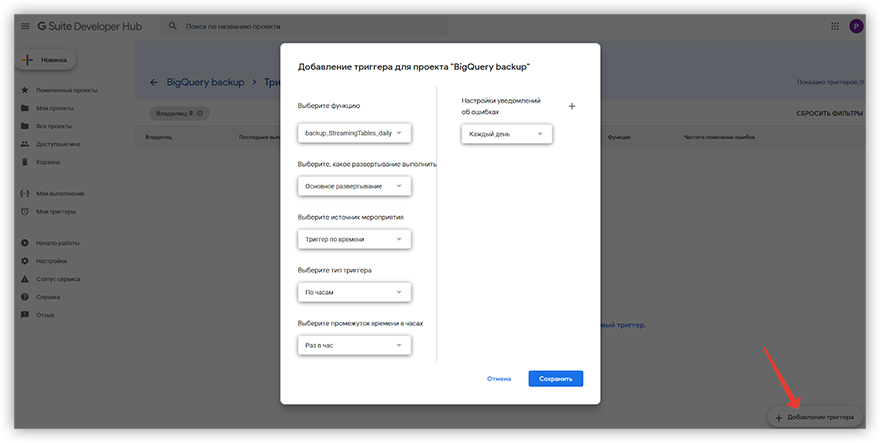
Когда придет время запуска, проверьте, сработал ли триггер. Если сработал, то в списке триггеров будет указано время срабатывания и статус. Если скрипт отработал без ошибок, то в GCS по соответствующим путям появятся наши резервные копии.
Восстановление из резервных копий
Если все это оказалось не зря и резервные копии понадобились, вы можете восстановить одиночную таблицу вручную или написать скрипт для массового восстановления.
Вручную всё просто: открываем BigQuery, жмем Create Table, в качестве источника выбираем Google Cloud Storage и указываем путь к файлу в хранилище, устанавливаем формат JSON (Newline Delimited). Рекомендуем не полагаться на автоматическое определение схемы, а указать ее явно. Задав все настройки, жмем кнопку Create Table.
Если таблиц множество, то проще запустить скрипт, который создаст в BigQuery работы на импорт
для каждой. Для единичной таблицы скрипт выглядит так.
Для обхода множества датированных таблиц оберните функцию в цикл, в котором на каждом шаге будет формироваться имя файла бэкапа и целевой таблицы.









